Suitable for large land area coverage but will not provide any detailed data.
1 m
Provides some level of detail but will hinder detection and measurement objectives.
30 cm
The highest detail available and ideal for object identification and mapping.
The power of 30cm Very High Resolution (VHR) satellite imagery lies in its ability to detect small objects. It allows you to achieve a level accuracy that’s necessary in order for your project to succeed. Through use of the WorldView-3 satellite and our ground control station near Munich, Germany, we are able to proficiently deliver 30 cm and other VHR imagery to you.
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.DENYCUSTOMIZEACCEPT ALL
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.
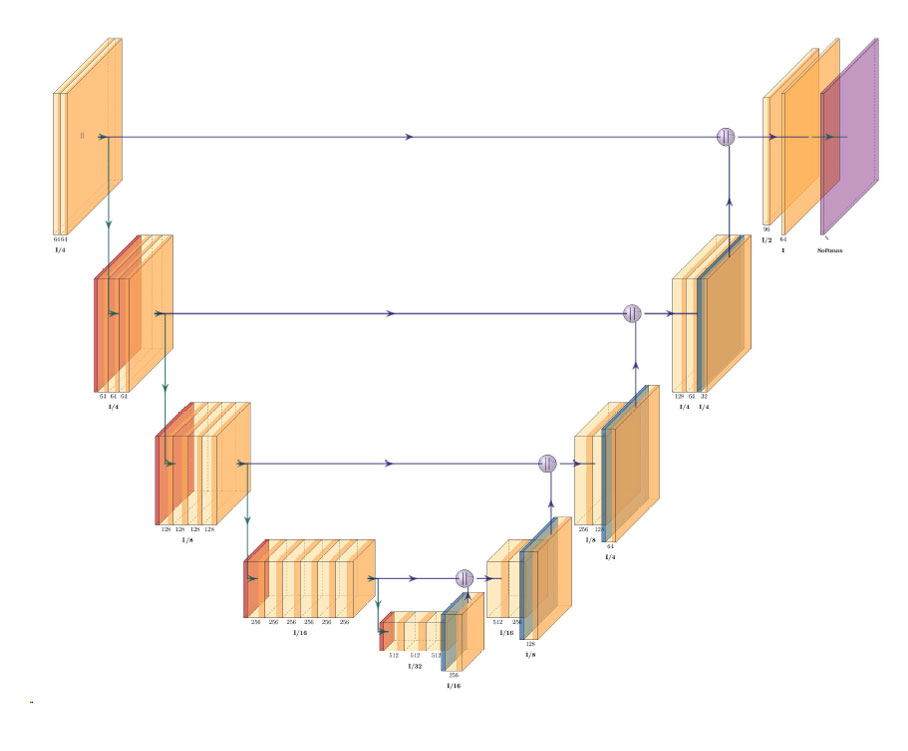
Architecture of ResNet34-UNet model
UNet architecture for semantic segmentation with ResNet34 as encoder or feature extraction part. ResNet34 is used as an encoder or feature extractor in the contracting path and the corresponding symmetric expanding path predicts the dense segmentation output.
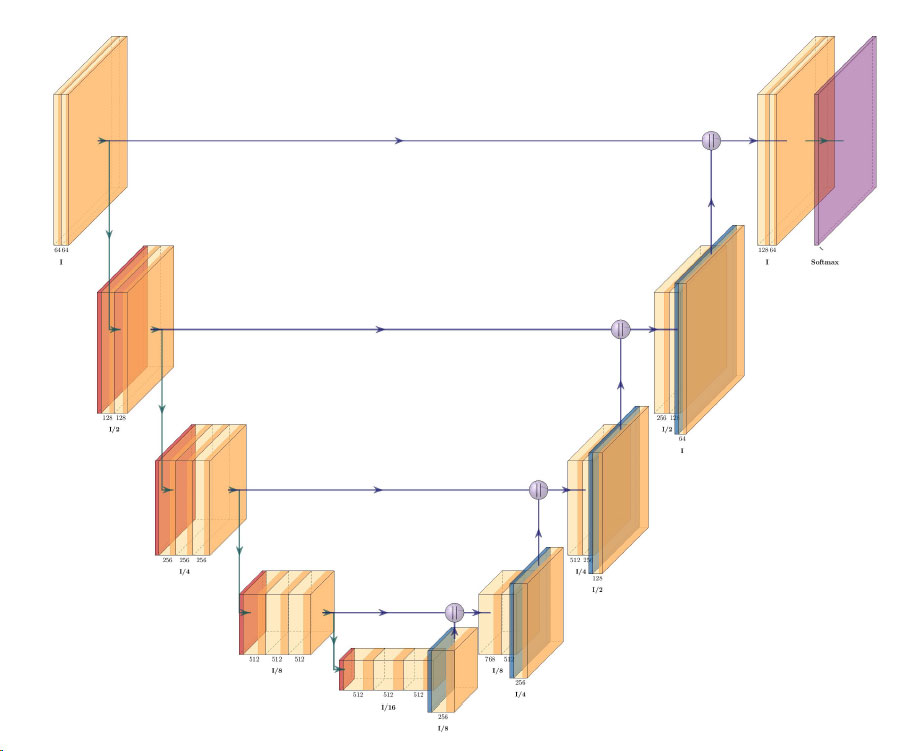
Architecture of VGG16-UNet model
UNet architecture for semantic segmentation with VGG16 as the encoder or feature extractor. VGG16 is used as an encoder or feature extractor in the contracting path and the corresponding symmetric expanding path predicts the dense segmentation output.
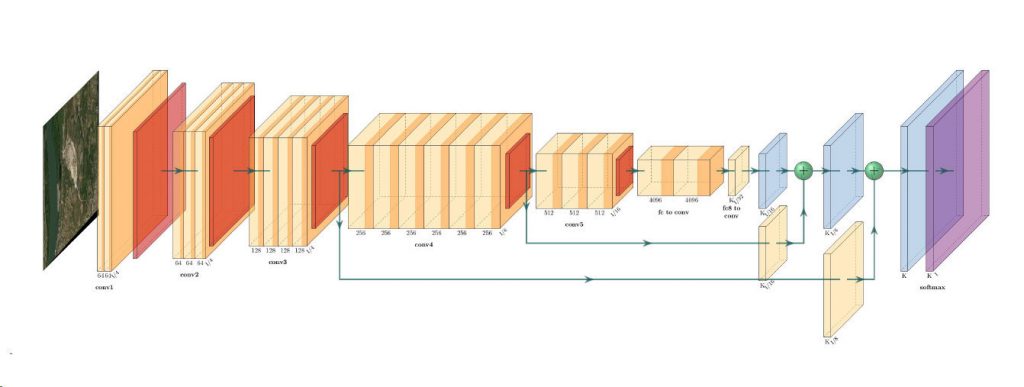
Architecture of ResNet34-FCN model
In this model, ResNet34 is used for feature extraction and the FCN operation remains as is. The feature of ResNet architecture is exploited where just like VGG, as the number of filters double, the feature map size gets halved. This gives a similarity to VGG and ResNet architecture while supporting deeper architecture and addressing the issue of vanishing gradients while also being faster. The fully connected layer at the output of ResNet34 is not used and instead converted to fully convolutional layer by means of 1×1 convolution.
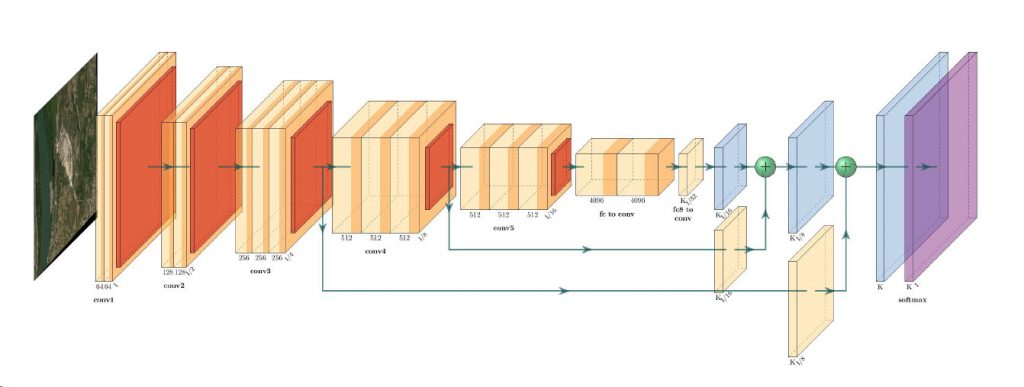
Architecture of VGG16-FCN model
In this model, VGG16 is used for feature extraction which also performs the function of an encoder. The fully connected layer of the VGG16 is not used and instead converted to fully convolutional layer by means of 1×1 convolution.