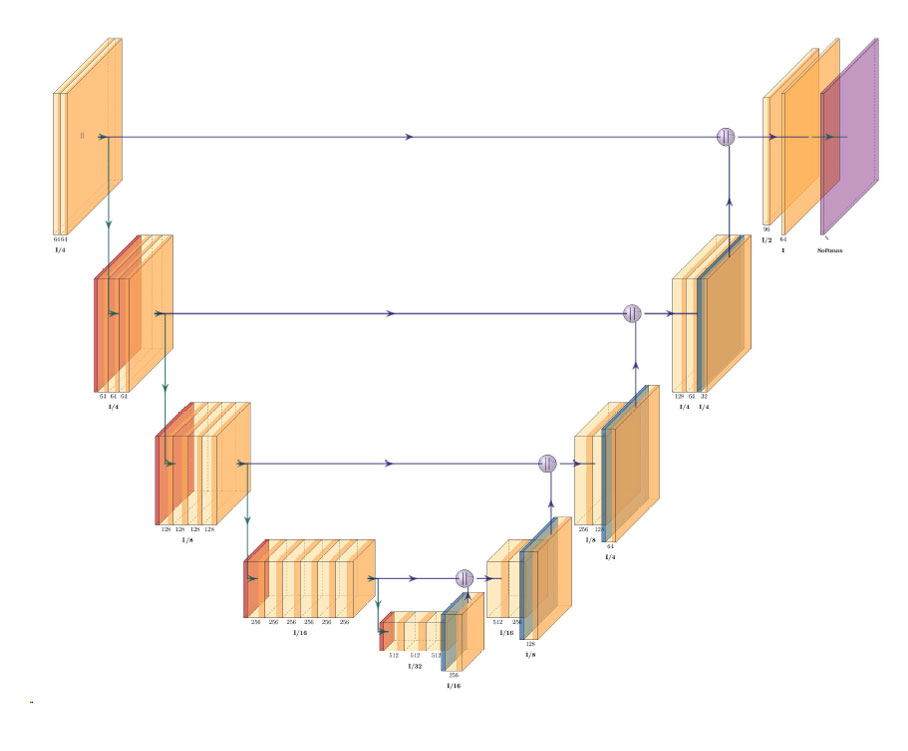
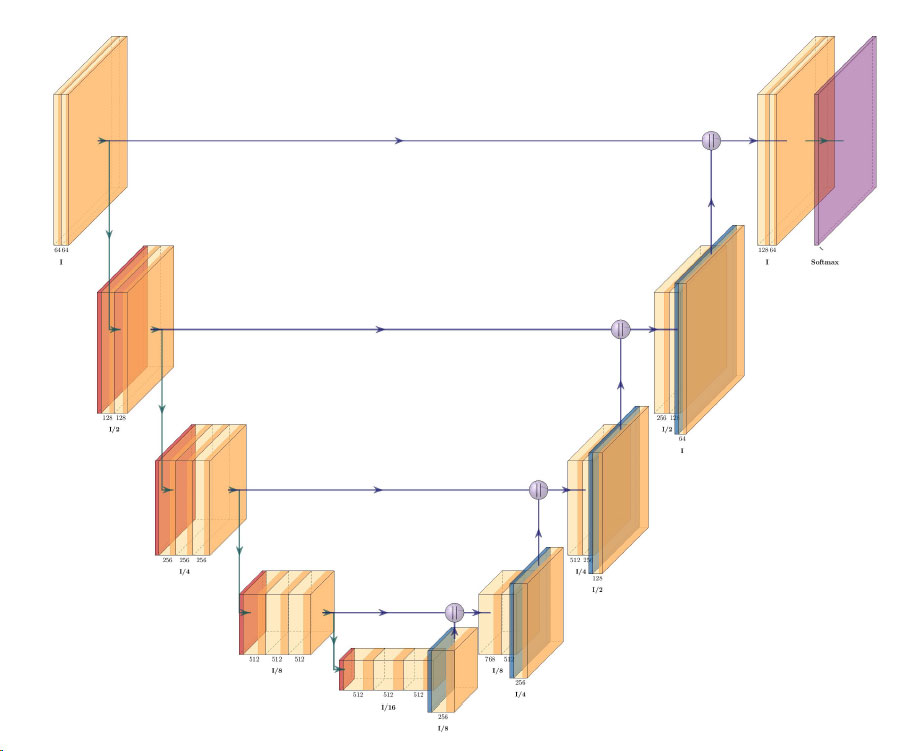
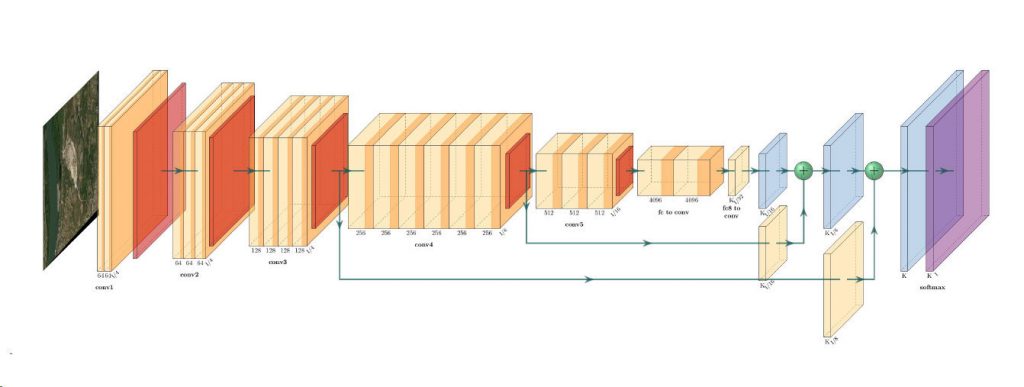
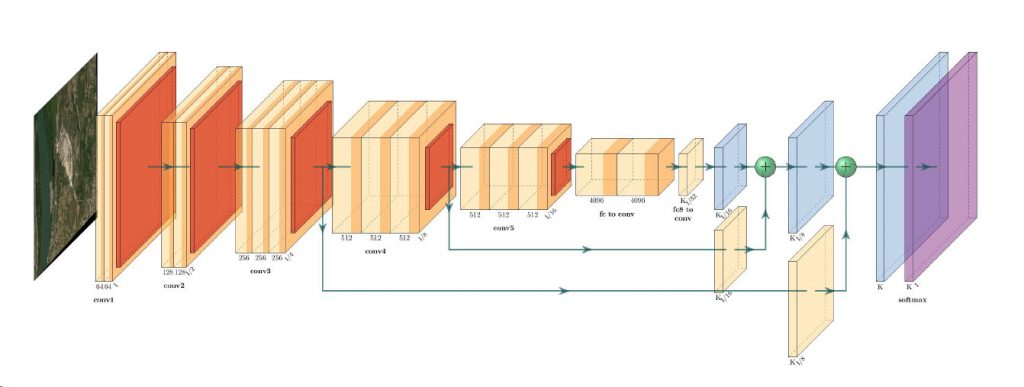
GEOSeries: Extracting Insights From High Resolution SAR Imagery for Time-Sensitive Analysis
In this webinar, industry experts and advanced users of Umbra SAR data showcase how they transform SAR imagery into actionable insights in real-world mapping, monitoring and intelligence applications. See how NV5 and Umbra leverage ENVI SAR Essentials for advanced processing with time-efficient results, converting analytics into valuable intelligence.

The Successful Launch of Maxar’s WorldView Legion and the Impact on European EO Applications
The first four long awaited WorldView Legion Satellites are now orbiting Earth. What does this mean for space-based remote sensing projects around Europe? In this webinar, EUSI is joined by representatives from Maxar Technologies. We discuss the unique technology within these satellites and how this significant increase in capacity of 8-band multispectral 30 cm class imagery is already poised to impact ongoing projects and increased demand across all sectors including Large Area Mapping, Security, Emergency Response, Agriculture and Research/Education.

MGP Pro Demonstration
Instant access to VHR satellite imagery via web or API. European Space Imaging recently recorded

MGP Pro: The Next Generation of SecureWatch for On-demand Access to VHR Imagery
MGP Pro provides unrivalled coverage, quality and flexibility. Its subscribers can access over 3 million square kilometers of daily image collections, plus more than 6 billion sq km of archived imagery at up to 30 cm resolution.