Easier to interpret images and better training material for AI/ML platforms
ACCURATE IDENTIFICATION
Increased level of detail available to accurately identify features
FASTER ANalysis
Faster interpretation driving rapid and more confident mission decisions
When your organisation’s business decisions require you to identify small features on the ground, an improved visual experience is key. The identification of objects such as road lines, individual plants, building edges and vehicles often requires the highest level of visual clarity. True 30 cm resolution imagery has long been the industry leader in clarity. Now with innovative proprietary technology applied to native 30 cm data, 15 cm HD imagery provides the next level of detail – enhancing manual and automated feature extraction efforts from satellite imagery.
15 cm HD is achieved through a process that intelligently increases the number of pixels in a native 30 cm resolution image, resulting in an improved visual experience. Not limited to any certain resolution, HD technology can also be applied to native 40-60 cm imagery, rendering a 30 cm HD image and thus, increasing the availability of 30 cm resolution imagery across the historical archive.
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.DENYCUSTOMIZEACCEPT ALL
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.
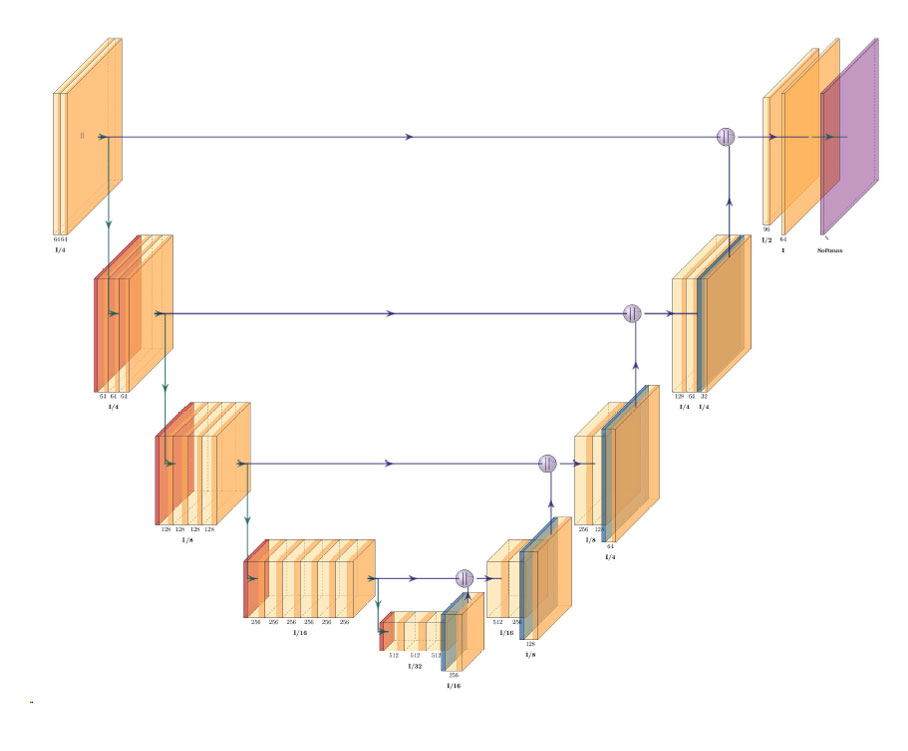
Architecture of ResNet34-UNet model
UNet architecture for semantic segmentation with ResNet34 as encoder or feature extraction part. ResNet34 is used as an encoder or feature extractor in the contracting path and the corresponding symmetric expanding path predicts the dense segmentation output.
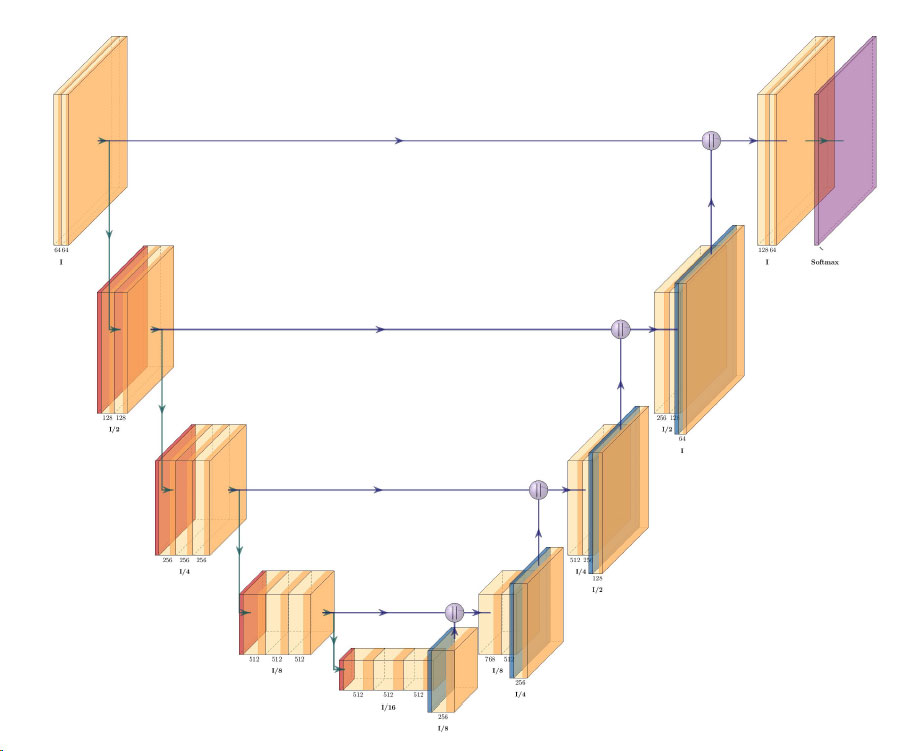
Architecture of VGG16-UNet model
UNet architecture for semantic segmentation with VGG16 as the encoder or feature extractor. VGG16 is used as an encoder or feature extractor in the contracting path and the corresponding symmetric expanding path predicts the dense segmentation output.
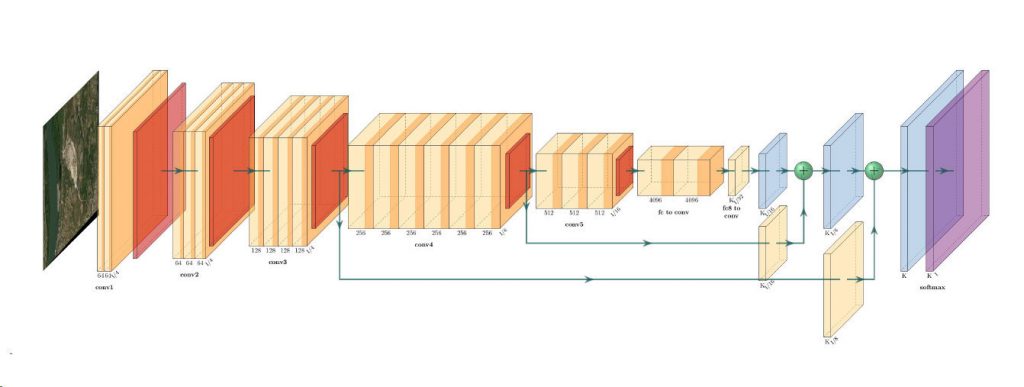
Architecture of ResNet34-FCN model
In this model, ResNet34 is used for feature extraction and the FCN operation remains as is. The feature of ResNet architecture is exploited where just like VGG, as the number of filters double, the feature map size gets halved. This gives a similarity to VGG and ResNet architecture while supporting deeper architecture and addressing the issue of vanishing gradients while also being faster. The fully connected layer at the output of ResNet34 is not used and instead converted to fully convolutional layer by means of 1×1 convolution.
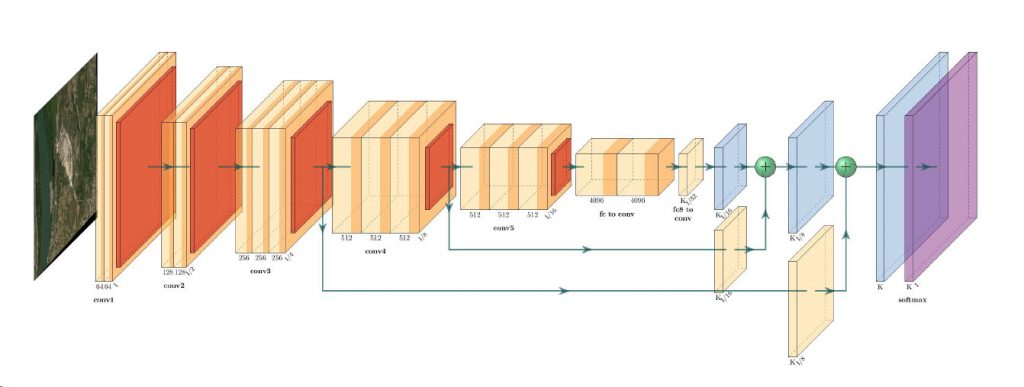
Architecture of VGG16-FCN model
In this model, VGG16 is used for feature extraction which also performs the function of an encoder. The fully connected layer of the VGG16 is not used and instead converted to fully convolutional layer by means of 1×1 convolution.